Booleans, lists, hashtable, and graphs constitute the basic libHLS
data structures. These are generic data structures. Let's start with them.
Booleans
This is a binary type having two values: TRUE and FALSE. In the C implementation,
FALSE equals zero and TRUE equals one. This is convenient since writing
something like:
Boolean c;
.
.
if (! c) {
..
}
makes sense when read. "If not c, then . . . "
Lists
Lists in libHLS are doubly-linked lists. This means they are one-dimensional
chains of items each of which points to its immediate neighbors. So if
youstart at the head of a list, you can move from one item to the next
until you reach the tail of the list. This is called "traversing" a list.
The list is said to be doubly-linked since you can move in both directions:
head to tail and tail to head.
Each item in the list points to a data structure. This data structure
is something you define. It is the data you want to place in the list.
When you tell libHLS to insert the data in the list, libHLS creates an
L_Item,
links it in appropriately, and makes it point to where your data is. Your
data is the real item. But libHLS implements it as "hanging off" an L_item.
You'll never see an L_Item when you work with libHLS, but it's
an example of how libHLS has a lot happening under the hood that you don't
see. You'll see directives all over the libHLS documentation telling you
to use only the function interfaces to manipulate data structures. This
is because the functions are designed to keep everything under the hood
working together correctly. If you open the hood, all bets are off.
Anyway, here's what a list really looks like. The dotted box is the
container you see. Everything in it gets hidden from you.
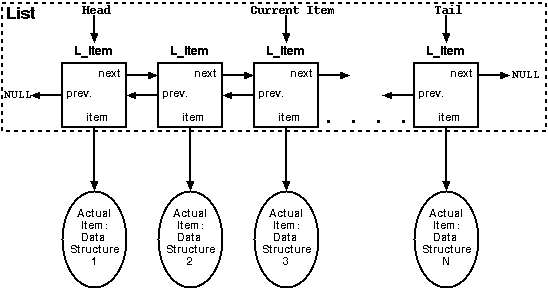
Each list maintains a pointer to its head item, its tail item, and an
item called the current item. Let's explain the current item a bit more.
When you traverse a list, you might start at the head and work your way
toward the tail. However, each time you move you need to keep track of
your current position in the list. The current item pointer does this.
Each time you move, it gets updated. The internal code representing a move
looks something like this:
List *l;
.
.
l->curr = l->curr->nxt;
.
.
What this does is update the current item pointer (l->curr)
with the pointer to the next item on the list. This pointer is stored in
the "next item" field (nxt) of the current item. Similarly, there
is a pointer for the "previous item" stored in the prv field.
The last item has it's next item field set to NULL or zero. Similarly,
the first item has it's previous item field set to NULL. So to detect when
you've reached the end of a list, you keep moving in one direction until
you see the current item pointer become NULL.
Constructors: Creating
a list
So how do we create a list? Simply saying "List l" is not good
enough since this just allocates space for the list data structure and
does not initialize it. And then . . . what about the other data structures
inside the dotted box in the figure above. Something needs to initialize
them too. This is why we always declare list pointers and then use the
list function "l_new()" to allocate memory for a list and all
its constituent data structures and to initialize them. l_new()
returns a pointer to the newly allocated and initialized list.
All data structures in libHLS have a similar "constructor" function.
Typically, if the data structure is called XX then the constructor
is XX_new().
All the functions in the list function interface operate on list pointers.
The libHLS Quick Reference guide lists them all.
Our first
libHLS program
Let's use these functions to create a list, put some data in it and
do something with it.
List *l;
int a[10];
int c, *i;
/* Create list */
l = l_new();
/* Put stuff in the list */
for (c=0; c<10; c++) {
a[c] = c; /* Set value of a[c] */
l_append(l, &a[c]); /* Place a[c] at
end of list */
}
/* Let's sort the list in order of decreasing
value */
l_sort(l, compareFunction);
/* Traverse the list from head to tail printing
the value of the items */
l_fforeach(l, i) {
} l_endfor;
/* Destroy the list */
l_free(l);
Dissecting
the example
This example illustrates some interesting things. It shows you how you
create a list using l_new().
Inserting items
in the list
The for loop shows you how to place things on the list. We
do that by appending data to the end of the list. Since the list starts
out empty, the first time we l_append() something, it becomes
both the head item and tail item of the list. Every subsequent time we
do that, the item becomes the tail item. There are other ways to insert
items on a list. l_prepend() places the item at the head of the
list. l_ins() inserts the item between the current item on the
list and its previous item.
Look closely at the l_append() line. Notice how we use &a[c]
as the item and not a[c]? This is because the type of the second
argument to l_append() must be the pointer to the data structure
we want to hang off the list item. Actually, the type is (void *).
This means it can take any pointer type. In our case, we're using (int
*).
Sorting a list: An introduction
to function pointers
Moving on. We sort the list. This means re-ordering the list items based
on a criterion. This criterion is supplied by the compareFunction.
This construct is worth a closer look, it appears in many different functions
in libHLS. The definition of l_sort() is:
void l_sort(List *l, int (*cmpFnc) (void *a,
void *b));
The second argument may look strange if you're still a C novice. It's
called a "function pointer". It corresponds to the location of a function
in your executable. You can execute a function referenced by a pointer
by executing the contents of the pointer. The usage is a little different
from regular data structure pointers. In our example, we would have to
define a function called compareFunction somewhere in our code.
For instance,
int compareFunction (int *a, int *b)
{
if (*a > *b) return 1;
else if (*a == *b) return 0;
else return -1;
}
The pointer to the function is simply compareFunction not
&compareFunction. Something like how for an array, a[10],
you use "a" as the pointer and not "&a". The function
can be called by the function pointer. For instance:
int (*foo) (void *, void *);
foo = compareFunction;
foo();
would actually call compareFunction().
So returning to l_sort(), the second argument points to a function
specifying the sorting criterion. Given two arguments, x and y, the function
should return a 1 if x is "greater" than y, a 0 (zero) if x is "equal"
to y, and a -1 if x is "less" than y. l_sort() then repeatedly
calls its cmpFnc() to sort the list so that the "greatest" item
first. It uses a merge sorting algorithm to do this. In our compareFunction,
the "greatest" item is in fact the numerically larger integer. So the list
gets re-ordered so the largest item is first.
List looping
constructs: Traversing a list
Now we get to another very important construct. You'll see something
like this in a lot of other data structures in libHLS. It's a looping construct
that you can use to traverse a list:
l_fforeach(List *l, void *i) { . . . } l_endfor;
l_fforeach and l_endfor are actually C-preprocessor
macros defined in list.h.
The macros first rewind the current item pointer so it points to the
head of the list. Then for each loop iteration they move the pointer from
the current item to the next, until the current item pointer is detected
to have reached the end of the list (i.e. when it hits NULL).
In each iteration, the pointer to the real current item - the one that
was placed in the list (remember . . . items hang off the list) - is stored
in i.
If you wanted, you could also write a looping construct yourself. Here's
how.
List *l;
void *i;
l_rwd(l); /* Rewind the list */
while (!l_atend(l)) { /* While we're not
past the end of list */
i = l_get(l); /* Get the data at the current
item */
. . . /* Do something with it */
l_nxt(l); /* Move to the next item */
}
This shows you how to use 4 new list functions. All of them and others
are listed in the Quick Reference. There is a problem
with this construct though. It changes the current item pointer in the
list. Since a list has only one this means you can't nest two such looping
constructs. Think of what would happen if you did:
l_rwd(l);
while(!l_atend(l)){
}
Only the inner loop would actually work. By the time, we got past one
run through the inner loop, the current item pointer is now NULL.
When the outer loop checks to see if we've reached the end of the list,
the answer is yes and the outer loop exits immediately even though it has
only performed one iteration.
l_fforeach() { . . . } l_endfor; gets around this problem by
storing the original current item pointer and then restoring it at the
end of the loop. So you can nest these constructs.
l_fforeach() starts the loop and l_endfor ends it.
You MUST have an l_endfor at the end of the loop, otherwise you'll
get a long stream of compiler syntax errors which look like junk. If you
do, there's a good chance you missed an l_endfor somewhere in
your code.
Also, notice how we use an integer pointer to hold the current "item"?
This is because we only store pointers in the list items. So we can only
retrieve the pointers. But that's good enough, since that leads us to the
data structure we've hung off the list item.
Fast versus
safe traversal: Two different looping constructs
There are two type of these looping constructs. The one we've seen is
l_fforeach().
The other is l_sforeach(). This stands for "safe foreach" and
the former for "fast foreach". The difference is that the safe version
makes a temporary copy of the list while the fast version doesn't. Making
a copy can be time consuming, which explains the name of the fast version.
However, the safe version is aptly named as well. Since it traverses a
copy of the original list, any changes you make to the list within the
loop body don't affect the traversal. This can be seen from the following
code:
l_fforeach (l, i) {
l_del(l, i); /* Remove item i from list */
} l_endfor;
If we wanted to empty a list with this construct it would fail. This
is because of the l_nxt() that is part of the l_endfor
macro. What would end up happening is that every second item would be removed
from the list. If we replace l_fforeach with l_sforeach
we would be traversing a different list from the one items were being removed
from. So we would traverse each element and successfully remove them all.
If this is confusing, write out the looping construct using l_rwd(),
l_atend(),
l_get(),
and l_nxt(). Put the l_del() in the loop body and work
out what would happen when the code is run.
A word of caution. Since l_sforeach makes a copy of the list,
l_endfor
must free the copy. If you return out of the function, l_endfor
has no chance to do this and a memory leak ( a chunk of allocated memory
which no longer has a pointer to it and which is effectively lost to the
program, but is still assigned to it by the operating system) would occur.
break'ing
out of and continue'ing an sforeach loop are legal. You'll
find safe and fast versions of looping constructs in the function interfaces
of many libHLS data structures.
Destructors: Cleaning
up the mess
And finally, we use l_free() to destroy the list. Why? Well,
we need to destroy all those internal list item data structures too, right.
If we don't we'd have a lot of memory leaks.
l_free() is a "destructor" function. A generic type,
XX,
would have a destructor called XX_free(). The destructor takes
care of cleaning up the data structure hierarchy under XX and
hides it from the user.
Once again, refer the the Quick Reference Guide
for all the list manipulation functions.
Hashtables
If you've got here and are still following along, let me say the hardest
part of this tutorial is over. While you learned about lists, you also
learned much of the coding style for using libHLS. From here on in, I'll
just tell you about the mechanics of each new data structure. Once you
know that you will be able to look up the Quick Reference
Guide for the function interface for the data structure. Let's move
on to your third libHLS data structure . . . a hashtable.
A search for an item in a list requires linear-time. This means you
may have to visit each item in the list before you find the one you want.
If you're doing searches a lot, this can be computationally expensive.
Hashtables provide a more efficient solution.
In a hashtable, each item inserted is given a unique key (or a name).
The key is used to access the item. Now if it were just the key, then you'd
still need to search all the keys in order to find your item. This is still
a worst-case, linear-time operation. Hashtables get around this by translating
the key to an integer in constant-time. This is done with a function called
a hashing function. The integer is then used to index into an array of
"slots". Each slot contains a linked list of items whose keys hash into
the same integer. The figure below illustrates this.
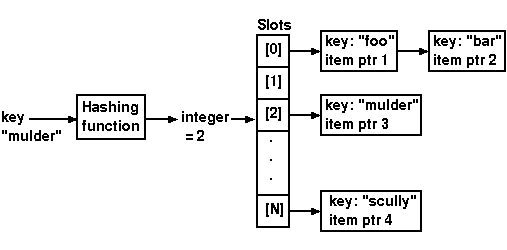
This method of resolving "collisions" (the event where two keys hash
into the same integer) is called chaining. When searching for an item,
we need to search only the list corresponding to the slot the key resolves
to.
If there are no collisions, the search can be performed in constant-time.
In the worst case, you still need linear-time (for instance, if all keys
hash into the same integer). But if we assume a well chosen hashing function
that evenly distributes the keys across the slots, then the average search
time is n/N. Where n is the number of items that are
in the hashtable and N is the number of slots in the hashtable.
Clearly as more items are placed in the hashtable, the search time worsens.
We can compensate by dynamically growing the hashtable. libHLS's hashtable
size doubles every time the number of items in it exceeds twice the size
of the hashtable. This keeps the n/N ratio less than the constant
2, theoretically resulting in a constant-time search.
This dynamic resizing, if it occurs very frequently, can prove expensive,
so there are ways to turn it off and also set the size of a hashtable manually.
Most of the time, you don't have to bother. Just let libHLS do its thing.
A hashtable is created in libHLS with a ht_new() function call
and destroyed with an ht_free() call. The keys are strings. The
hashing function is internal and you need not be concerned with it. The
basic operations are item insertion, search, and deletion. These are done
with the ht_ins(),ht_get(), and ht_del() calls
respectively.
Once again, the items placed in the hashtable are referenced by their
pointers. So they really "hang" off the hashtable's linked list items.
As there were for lists, there are hashtable looping constructs as well:
ht_fforeach(HashTable *h, const char *key,
void *data) {
} ht_endfor;
and the corresponding "safe version" ht_sforeach() { ... } ht_endfor;
Here's some sample code.
int a[10];
int c;
HashTable *h;
char b[10];
/* Initialize the hashtable */
h = ht_new();
/* Fill it */
for (c=0; c<10; c++) {
sprintf(b, "%d", c); /* Create key */
/* Insert item. Hashtable maintains
its own internal copy of key */
ht_ins(h, b, &a[c]);
/* Note it doesn't matter if we set the
value of a[c] after we insert it. The
hashtable only keeps a pointer to a[c],
not the value. */
a[c] = c;
}
/* Search for element named "5" */
b = ht_get(h, "5");
/* Check we found it */
if (b != NULL) {
}
else {
printf("Didn't find it.\n");
}
/* Free the hashtable */
ht_free(ht);
The complete hashtable function interface can be found in the Quick
Reference.
That's all there is to it. You now know everything you need to know
about using hashtables. Let's move on.
Graphs
Graphs are central to high-level synthesis and therefore libHLS. Graphs
are complex data structures that use three other libHLS data structures:
Nodes, Edges, and UEdges.
Let's define graphs. Graphs contain nodes interconnected by directed
edges and undirected edges. A directed graph has a direction and therefore
a source and destination node. An undirected graph has no direction, just
two endpoint nodes.
In graph theory, graphs are classified as directed if they have directed
edges and undirected if they have undirected edges. In libHLS, a graph
can have both types of edges. This allows you, the user, flexibility to
choose whether or not to have a mixed directed/undirected graph.
Graphs, nodes, edges (directed edges) and uedges (undirected edges)
are all objects in libHLS. Each has a constructor and a destructor. Normally,
you'll never have to create a node, edge or uedge manually. Since they
typically belong to graphs, the graph function interface contains functions
to add nodes, edges, and uedges and also to remove them. In fact, when
you build a graph you MUST use the graph interface's functions. This
is because there are lists and hashtables maintained within the graph's
data structure which must be kept consistent. The graph interface's functions
ensure this. Remember what I said earlier about the dangers of mucking
around under the hood? Here's a good example of where you can get yourself
in trouble by doing this.
You should never need to use the constructors and destructors for node,
edges, and uedges, but they are provided in the interface in case you need
to create such objects independent of a graph.
Here's what a libHLS graph might look like.
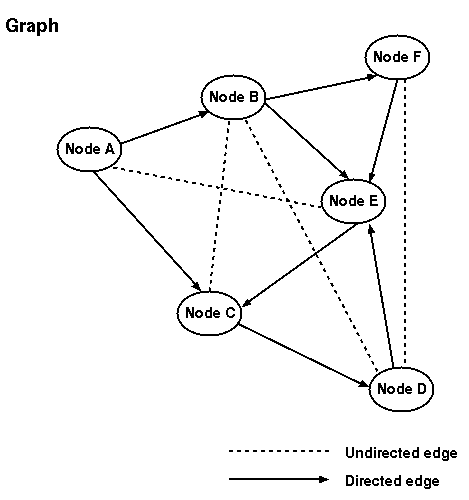
Graphs: Graphs contain lists of nodes, edges and uedges. In addition,
they maintain hashtables for the same to enable constant-time access to
the objects when requested by name.
Graphs also have an ordered list of inports and outports. These are
nodes with no incoming directed edges and outgoing directed edges respectively.
If this graph is part of a graph hierarchy and is represented as a node
in a higher-level graph, then the incoming directed edges to the node representing
our graph in the higher-level one get connected to the inports of our graph
at its level. The edge to inport mapping is defined by the order of nodes
in the inedges list of the node at the higher level and the inports list
of the graph at its level. The same happens with the outports and outgoing
directed edges. Hierarchical graphs are still not supported within libHLS,
but will be eventually. In the meantime, inports and outports are supplied
for the "do-it-yourself"ers among you.
Nodes: Nodes have lists of incoming directed edges, outgoing
directed edges, and incident undirected edges.
Edges: Directed edges have a pointer storing the source node
and another storing the destination node.
UEdges: Undirected edges have two pointers (n1 and n2) for storing
the two endpoints of the uedge. Except for the functions to set and get
them, these two are treated interchangeably by all uedge related functions
in libHLS.
Graphs, nodes, edges, and uedges have some elements in common. Each
data structure has a name field. The name is used as a unique identifier
for the object. The name is a string and the object keeps a private copy.
They also have an attribute table storing attributes of the object.
Attributes have string names and string values. The object concerned keeps
its own private copy of both the name and value strings.
All the objects maintain a properties table. Properties have string
names but their values are pointers to any data structure. This allows
you to annotate all the objects with any information you want. The object
keeps a copy of only the name string.
Attributes are a special case of properties since their values must
be strings. However, when you write a graph to a file, the attributes get
written. Properties do not. Similarly, attributes get read from the file.
So attributes are useful when you want to save and recover information.
However, it is necessary to convert data structures into strings in order
to use attributes for this purpose.
Internally, attributes and properties are stored in hashtables keyed
with the attribute or property name. Sometimes looking up attributes and
properties might take longer than you want. To solve this problem, each
graph, node, edge and uedge also maintains a single element called user
information. You can hang any data structure you want off of it. There
are functions in the interface to set, recover and clear the user information
field. Referencing user information is only a pointer dereference in C
and is very fast.
The function interface to each of these data structures is detailed
in the Quick Reference Guide. Here's an example
of a program that uses the graph function interface.
Graph *g;
Node *n1, *n2;
UEdge *ue;
char buf[1024];
/* Read the graph from a file */
g = graph_read_from_file("graph1.graph");
/* Verify it was read successfully */
if (!g) {
warn("Error reading graph from graph1.graph.\n");
return;
}
/* For every pair of distinct nodes, do */
l_fforeach(graph_nodes(n), n1) {
} l_endfor;
/* Write the modified graph to file */
graph_write_to_file(g, "graph1.modified.graph");
Private Fields
In the Quick Reference and the User Manual, you'll see references to
certain values returned by functions as being "private". What this means
that this is an internal copy of some data that is used by a libHLS data
structure. You are forbidden from modifying private data!
You can
only perform passive operations on them. For strings, this means reading
them, finding their length, comparing them with other strings. Copying,
concatenating or modifying them in any way is forbidden. The same goes
for lists and other data structures tagged private. You can read them,
but don't change them. libHLS functions sometimes need to change multiple
elements of a data structure in order to keep the data in them consistent.
If you change one element without changing another, you might leave the
data structure inconsistent which will cause your program to crash. Remember
the stuff I said about messing around under the hood?
Here's an example:
Node *n;
List *nl;
/* Get nodes of graph */
nl = graph_nodes(g);
/* While the list is not empty do */
while(!l_isempty(nl)) {
/* Get the first node on the list */
n = l_first(nl);
/* Perform some operation on the node */
. . .
/* Remove the node from the list since we've
taken care of it */
l_del(nl, n);
}
This is illegal code, since you're removing nodes from the graph's internal
nodelist.
graph_nodes() is a function that returns a pointer to the
graph's private nodelist. You shouldn't modify it. The correct way to do
something like this is to make a copy of the list.
/* Get nodes of graph */
nl = l_copy(graph_nodes(g));
Remember to destroy your copy with l_free() when you're done.
Note: The nodelist is private and shouldn't be changed with a
l_XXX()
function. The nodes are private too, but their properties, attributes,
and user information can be changed. What's private (and therefore must
not be changed without the graph_XXX() functions) is the topological
relation of the node with the other objects in the graph. This may seem
confusing at first, but you'll get the hang of it.
Displaying
a graph with XVCG
One of the nicer features of libHLS is that it allows you to visualize
and animate a graph from a C program. It does this using the graph visualization
package, XVCG. To use this feature, all you do is say:
graph_display(g);
where g is a graph. The display manager takes care of all the
details. Internally, it maintains a list of which graphs are currently
being displayed and which XVCG processes are doing it. It uses the graph's
name to identify the XVCG process. So it's a good idea to make sure that
each graph has a different name. Otherwise, you'll get some "interesting"
animations.
If a graph isn't currently being displayed, the display manager launches
another XVCG window and displays the graph in it. If the graph is currently
being displayed, the display manager communicates with the relevant XVCG
process and tells it to update its display for the current state of the
graph. So to animate a graph being processed/changed you display it, change
it, display it again, change it again and so on. The dfs
example shows you how to do this.
Occasionally, an XVCG window will die on its own, usually because the
X-server you're running on is too slow. This sort of things usually happens
if:
-
you move the XVCG window before it has finished displaying the graph
-
you animate a graph by calling graph_display() repeatedly in quick
succession. The XVCG process can't complete displaying the graph before
it gets more information.
The display manager is designed to avoid the second problem. But sometimes
things do go awry. If they do, the display manager detects the XVCG process
has died and restarts it.
If the display manager is having a LOT of trouble with dying XVCG processes,
I usually insert a pause_til_keypress() function call after each
graph_display()
call. This makes the program wait for the user to hit the RETURN key before
continuing. This allows you to wait until the display stabilizes and then
continue. You usually don't need this, but just in case . . .
To close a graph's display, use:
graph_undisplay(g);
and the display manager take care of shutting the display down. The
display manager also intercepts all controlled program exits like a call
to exit() or the user hitting Control-C. It makes sure to shut
down all XVCG processes before the program exits. However, if your program
crashes in an uncontrolled way (e.g. segmentation fault, bus error) then
the display manager may not be able to do this. You'll have to shut down
the XVCG processes yourself.
In the dfs example, you'll see I set certain
attributes of nodes that have a "vcg:" prefix. This is a special type of
attribute. The display manager intercepts all attributes with "vcg:", strips
the prefix from the attribute name and passes the remaining part of the
name and the value to the XVCG process as an XVCG attribute of the graph,
node, or edge. Valid XVCG graph, node and edge attributes can be found
in the manual page for XVCG. If you use an
invalid attribute name, the XVCG process will die on a syntax error caused
by data sent by libHLS to XVCG, so be careful. Some examples of valid XVCG
graph attributes are "color", "textcolor" and "label".
Function return
values on failure
Most libHLS functions return a pointer, integer or Boolean. When there
is a possibility that the function will fail (e.g. fail to find an edge
between nodes specified) then it will return a failure code. Unless specified
in the Quick Reference or User Manual, the default
failure codes are:
-
NULL for functions returning pointers
-
-1 for functions returning integers
-
FALSE for functions returning Boolean (this is usually self-evident)
Your code should check for failure conditions and handle them gracefully.
The central subproblems in HLS are resource allocation, operation scheduling
and operation binding. libHLS uses the graph data structure as the intermediate
form for a behavioral design. The nodes of the graph represent operations.
Directed edges represent precedence constraints. Each graph has a resource
reservation table data structure associated with it. This contains information
about the resource allocation and maximum number of control steps the design
is allowed. In the process of operation scheduling and binding, the resource
reservation table is updated.
First, let's define some terms so that we're all on the same page.
Some definitions
Operation: An operation is an action
in the behavior that requires a functional unit to execute. For example,
an addition, a comparison, a multiplication . . .
Resource: A resource is a component of the architecture that
may be used to implement part of the behavior. For example, an adder, a
bus, a register-file . . .
Dataflow graph: A graph data structure is used to represent a
dataflow graph (DFG). The nodes represent operations and the directed edges
represent precedence relations between operations.
Control step: The time available to the behavior to execute on
the synthesized architecture is divided into control steps. Typically,
a control step (cstep) is a single clock cycle. This is the definition
used in libHLS.
Maximum control steps: This a maximum number of control steps
available to the behavior. The DFG is annotated with this information.
For time constrained synthesis, this is a fixed number. In resource constrained
synthesis, this can be changed to reflect the transient maximum number
of csteps during synthesis.
Node operation type: A node of a DFG has an "operation" attribute
which specifies the type of the operation in the behavior. For example,
an addition.
Node resource type: This is the type of resource in the synthesized
architecture that will implement the operation of the DFG node.
Resource type (RType): This is a
libHLS data structure representing a specific type of resource in the synthesized
architecture
Resource instance (RInstance): There may be several resources
of a specific type in the synthesized architecture. Each is a resource
instance of that resource type. For example, each adder of a set of
4 adders in an architecture is a resource instance of the adder resource
type.
Resource allocation: Specifying
the number of each type of resource available in the synthesized architecture.
Operation scheduling: Specifying at which cstep each node (operation)
of the DFG will be executed.
Operation binding: Specifying which resource instance of a node
resource type will execute the node's operation.
Resource reservation table (RTable): A table storing scheduling
and binding information of the DFG. Its columns represent resource instances
and its rows represent csteps. When a node is both scheduled and bound
and entry is made for it in the resource reservation table.
Where the
information gets stored
libHLS uses the graph and node data structures to store HLS-specific
information. It assumes your behavioral description has been converted
to a set of DFGs and that you're operating on one DFG at a time. (Control
flow can be handled too. More on that later.) libHLS also stores the same
information in a variety of ways to provide quick access by several different
methods. The HLS-specific interface manages that, so you should be sure
to use it.
The resource reservation
table (revisited)
The resource reservation table is central to the HLS-specific interface.
Each DFG (Graph) has a single rtable data structure which encompasses information
regarding resource allocation, operation scheduling and operation binding.
Here's what the rtable looks like.
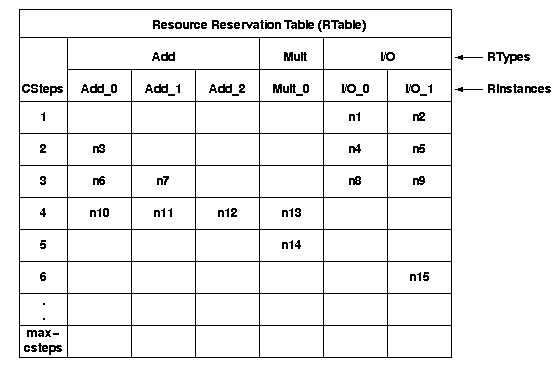
A design has resources for executing operations in the behavior. These
are entities like adders, multipliers, register file ports, . . . We differentiate
instances of resources from the type of the resource by defining two distinct
data structures: resource instances (RInstances) and resource types (RTypes).
So "Add" might be a resource type for an adder. But "Add_0" is the first
instance of an adder in a design with three adders. RInstance names can
be arbitrary, but must be unique. libHLS has a default naming scheme which
the rtable shows.
Typically (and therefore we assume), a resource instance can execute
at most one operation every control step. So if we set an upper bound for
the number of control steps available to the design, then each resource
instance can execute only that many operations. Each rinstance contains
an array with that number of elements. When a node is scheduled at a cstep
and bound to a rinstance, an entry is made in the appropriate element of
this array of the rinstance.
So to summarize, a resource reservation table is made up of rtypes.
Each rtype has a list of rinstances. Each rinstance has an array in which
scheduled and bound nodes can be recorded. A resource reservation table,
therefore, encapsulates resource allocation, operation scheduling, and
operation binding information.
Each DFG (Graph) keeps track of its resource reservation table and also
the maximum number of csteps assigned to it.
Annotating
nodes and edges of the DFG
As often happens in HLS, you usually have a node at hand and you need
to know when it was scheduled. You could have your HLS system look up the
node in the reservation table, but this would take way too long. So libHLS
annotates nodes with the scheduling information too. In fact, it also annotates
nodes with information regarding binding as well. So you can access both
quickly. But this means libHLS has to be entrusted with keeping all this
information consistent. Don't go about modifying this information manually!
libHLS also annotates some other information on the nodes. In order
to know which nodes represent operations that require a resource to execute
(add, multiply, compare) and which don't (placeholders, control structures),
each node has two reserved attributes:
-
"operation" which specifies that the node needs a resource and also what
the operation is.
-
"resource" which specifies the resource type this operation must be executed
on.
The two need not be the same. For example, an "add" and "subtract" operations
can be executed on an "ALU" resource type.
There aren't any annotations on the edges just yet. But there will be
in future versions of libHLS. They will have to do with data binding information
like register, register port, and bus binding. At present, you'll have
to keep track of that information manually.
Here's a hint: Use the user_info data structure on edges or nodes to
hold your own HLS-specific information.
Scheduling operations
You should use the node_schedule() function to schedule a node.
The function takes a node and control step as arguments. It returns a TRUE
or FALSE. The TRUE means the node was successfully scheduled. The FALSE
means it failed. Failures happen if one of two things occurred:
-
the node was previously scheduled at different cstep (you have to node_unschedule()
it first or use node_reschedule())
-
the node has been bound too, but the resource instance it was bound to
is not free at that cstep (it's been reserved for another bound and scheduled
node)
If your HLS algorithm is well-behaved, you can theoretically deduce failures
will never happen. However, this doesn't account for bugs in your code.
It reduces your coding cycle will very little computational overhead if
you check for failures.
Binding operations
The node_bind() function binds a node to a resource instance.
Its two arguments are a node and a resource instance. Like node_schedule(),
it too returns a TRUE or a FALSE. Failures happen in two similar conditions:
-
the node was previously bound to a different resource instance. (node_unbind()
or node_rebind() it)
-
the node was already scheduled but the resource instance is already reserved
at that cstep.
Once again, there's the same caveat about checking for failures.
Take a look at the quick reference guide for
more functions that have to do with scheduling and binding nodes. They're
pretty self-explanatory.
Retrieving
scheduling and binding information
The scheduling and binding functions ensure the resource reservation
table and the node annotations stay consistent. You can quickly retrieve
this information in a variety of ways.
-
if you have a node:
-
node_get_cstep()
-
node_get_rinstance()
-
if you have a resource instance:
Initializing a
resource reservation table
We've discussed how to bind nodes to resource instances, but not how
the resource instances were created in the first place. There are two ways
to do this.
Resource allocation
The first way is to create a resource allocation that specifies how
many of each type of resource are present in the synthesized architecture.
The various rallocation_XXX() functions allow you to create and
fill in a resource allocation data structure (RAllocation). You
then annotate the graph with the resource allocation using graph_set_rallocation().
When the resource reservation table is created using graph_init_rtable()
or a call to graph_rtable(), the resource allocation is retrieved
and used to fill in the rtable.
Adding
resource instances on the fly
Resource allocations are usually useful if you're working on a resource-constrained
HLS system. If you're working with a time-constrained system and are trying
to minimize the number of resource instances, it's useful to be able to
add resource instances during synthesis. You can do that by leaving the
graph's resource allocation empty. Then a call to the graph rtable initialization
functions (above) will generate and return an empty rtable. You can use
the pointer to the rtable and call rtable_add_rinstance() or rtable_add_rinstances()
to add resource instances on the fly.
Adjusting
the length of the schedule on the fly
What if we are working with a resource-constrained system and
want to minimize the number of csteps in the schedule. libHLS provides
a graph_set_max_csteps() function. This adjusts the length of
the arrays in each resource instance data structure to reflect the new
maximum number of csteps. If this number is smaller than the previous one,
nodes scheduled at csteps later than the new maximum cstep will be unscheduled
automatically.
This is useful to lengthen the schedule. To insert a cstep somewhere
in the middle of the schedule, you'll have to lengthen it and then reschedule
all the nodes scheduled after the insertion point later by one cstep.
Saving
and retrieving HLS-specific information
Once you've scheduled and bound all the operations in your application,
you might want to save your work. There is a convenient way to do this.
graph_register_hls_info() allows you to save the maximum number
of csteps, the cstep each node is scheduled at and the resource instance
each node is bound to. It does this by creating a graph attribute "max_csteps"
and node attributes "cstep" and "rinstance". Obviously, these now become
reserved attribute names. Now when you save the graph with a graph_write(),
these attributes get written to the graph file.
graph_retrieve_hls_info() can then be used to recover scheduling,
binding, and allocation information from the graph when it is read in using
graph_read().
The function will regenerate the resource reservation table and automatically
schedule and bind all nodes in the graph so the graph read in is now in
the same state it was when you saved it.
If there is other information you want to save and retrieve, you can
write wrappers around these two functions and convert that information
into attributes that you specify.
Displaying DFGs
with XVCG
The XVCG display manager in libHLS treats DFGs a little differently
from normal graphs. First, it looks for the "resource" and "operation"
types of nodes and displays nodes that are "in" or "out" operations or
use an "i/o" resource as yellow triangles. This differentiates inputs and
outputs of a DFG from the other nodes. The display manager also labels
each node with its name, as usual, but also adds its resource type beneath
it in brackets.
Unscheduled nodes are colored and are laid out by XVCG. The display
manager removes the color (actually sets it to the grey background color)
from scheduled nodes and forces it to be laid out in the XVCG display row
corresponding to its cstep. So as nodes are scheduled, you'll see them
turn transparent and move to their assigned cstep in XVCG.
When a node is bound, the resource type in its label changes to the
resource instance it is bound too.
So the display manager allows you to watch your synthesis algorithm
work. This is very useful for judging its performance and allows you to
tune it easily.
To animate your HLS algorithms, simply call graph_display()
after you've performed a synthesis action. It will be reflected immediately
in XVCG. A warning though . . . the display manager has to wait for XVCG
to display the graph, so using it to animate your HLS algorithm will slow
the algorithm down. You should design your code to allow turning off animation
easily when you have finalized your algorithm and no longer need to view
it work.
Computing timeframes
of operations of a DFG
While scheduling, the piece of information the scheduler most frequently
needs is the timeframe of an operation (node). The timeframe is the set
of csteps in the schedule at which the operation may be scheduled without
making any of the other operations unscheduleable. The timeframe is defined
by two csteps: the ASAP (as-soon-as-possible) cstep and the ALAP (as-late-as-possible)
cstep. These are the first and last csteps in the timeframe.
libHLS provides two functions for computing these values:
-
node_get_asap_cstep()
-
node_get_alap_cstep()
Both of these return integers representing the ASAP and ALAP csteps respectively.
Scheduling an operation may affect the timeframes of operations preceding
and succeeding it in the DFG. libHLS recomputes the timeframes of these
operations on an as-needed basis. When as scheduling action affects the
timeframe of a node, libHLS marks it as invalid. When a call to node_get_asap_cstep()
or node_get_alap_cstep() is made for that operation, libHLS recomputes
the ASAP and ALAP csteps at that time.
In addition, these functions compute (or update) the ASAP and ALAP csteps
of the operations preceding and succeeding the one whose timeframe has
been queried.
All of this happens in the background. As user, you will never see this
happen. You'll only see the effects. libHLS will always provide you the
most up-to-date timeframes of the operations in your DFG.
